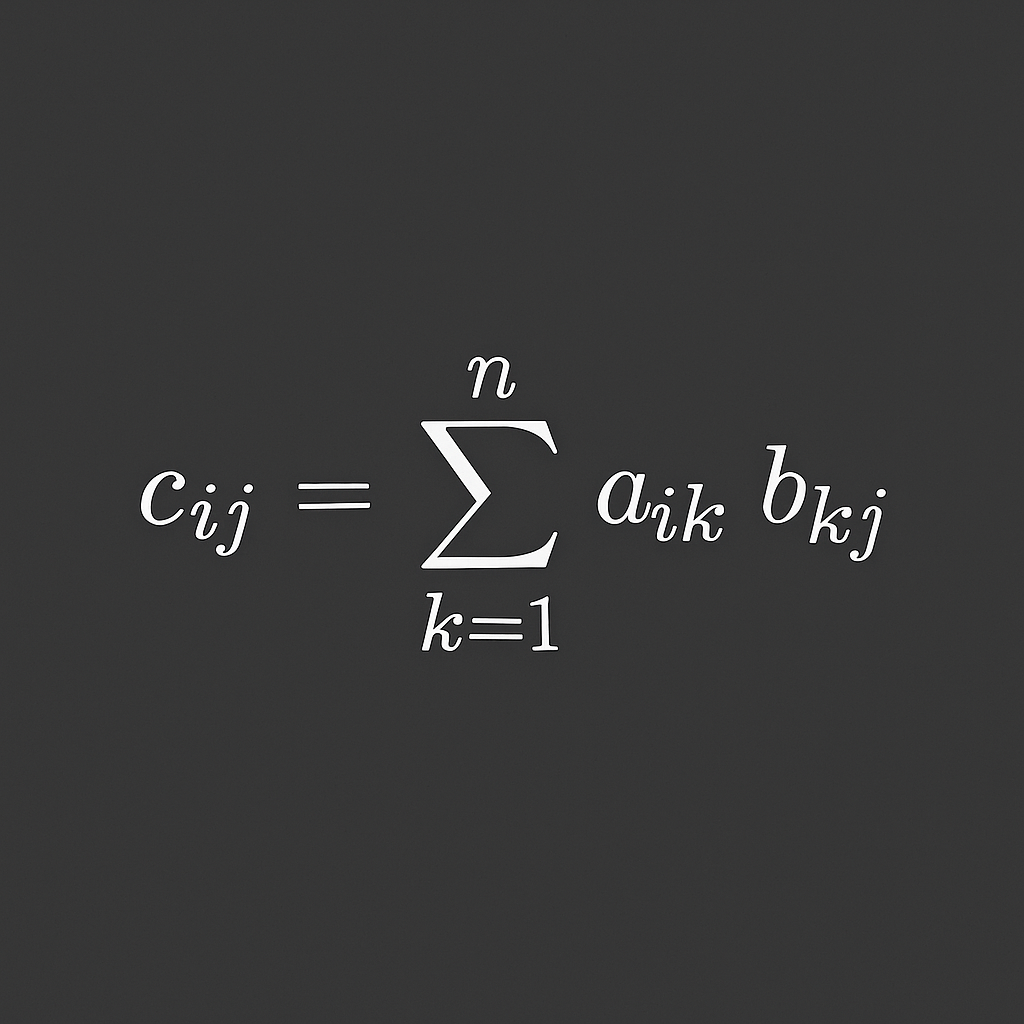
Matrix Multiplication and Its Importance in Artificial Intelligence
Matrix multiplication is one of the most essential operations in linear algebra, forming the backbone of modern machine learning and artificial intelligence. Even the most advanced AI models, such as Transformers and neural networks, internally depend on millions or billions of matrix multiplications every second.
In this article, we break down how matrix multiplication works and why it is indispensable in today’s AI landscape.
1. What Is Matrix Multiplication?
Matrix multiplication combines two matrices to produce a third one. If matrix has dimensions and matrix has dimensions , then their product is an matrix.
Matrix multiplication formula
This formula says that each element of the resulting matrix is the dot product between the corresponding row of and the corresponding column of .
Example
Matrices:
Product:
2. Why Matrix Multiplication Matters in AI
2.1 Representing Data
Machine learning models process data in matrix form. A dataset with samples and features is:
Operations on this dataset (transformations, projections, normalizations) are matrix operations.
2.2 Linear Models
A simple linear model computes predictions as:
Where:
- = input matrix
- = weights
- = bias
This is pure matrix multiplication.
2.3 Neural Network Forward Pass
In a neural network layer:
Every hidden layer, every transformation, every projection = matrix multiplication.
2.4 Backpropagation
During training, gradients such as:
are computed using matrix products and transpositions.
Deep learning frameworks like PyTorch, JAX, and TensorFlow are optimized around fast linear algebra (BLAS, cuBLAS, GPU kernels).
3. Transformers: AI Powered by Matrix Multiplication
The self-attention mechanism, the heart of GPT, LLaMA, BERT and all modern LLMs, relies heavily on matrix multiplication.
Attention formula:
Matrix multiplications involved:
- softmax applied row-wise
- product with
Without extremely optimized matrix multiplication, transformers could not run.
4. Computational Complexity
The naive complexity of matrix multiplication is:
This high computational cost is why:
- GPUs
- TPUs
- specialized matrix-multiply hardware
are essential in AI.
5. Why GPUs Dominate AI Training
Each output element:
can be computed independently.
This makes matrix multiplication highly parallelizable, and GPUs are designed for thousands of simultaneous operations. That’s why training an AI model is essentially a huge matrix-multiplication marathon.
Conclusion
Matrix multiplication is at the core of all AI systems. From simple linear regression to deep transformers, every stage of computation relies on efficient matrix operations. Understanding how these operations work is essential for anyone looking to become proficient in machine learning, AI engineering, or deep learning research.
Leave a Reply
Your email address will not be published. Required fields are marked *

Comments