Mode Imputation in Datasets: A Practical Guide to Handling Missing Data
Introduction
In data analysis and machine learning, one of the most common problems is the presence of missing values. These may occur due to data entry errors, sensor failures, incomplete survey responses, or system integration issues.
When a dataset contains null values, many tasks are affected: from basic statistical calculations to training predictive models. This is why it becomes necessary to apply techniques that systematically handle these values. One of the simplest and most widely used methods is mode imputation.
What is Mode Imputation?
Mode imputation consists of replacing missing values in a variable with the value that appears most frequently in that variable, known as the mode.
From a statistical perspective, the mode is defined as:
Where represents the frequency of value within the dataset .
This technique is especially useful when working with:
- Categorical variables (gender, country, product type)
- Nominal data
- Discrete variables with few categories
Conceptual Example
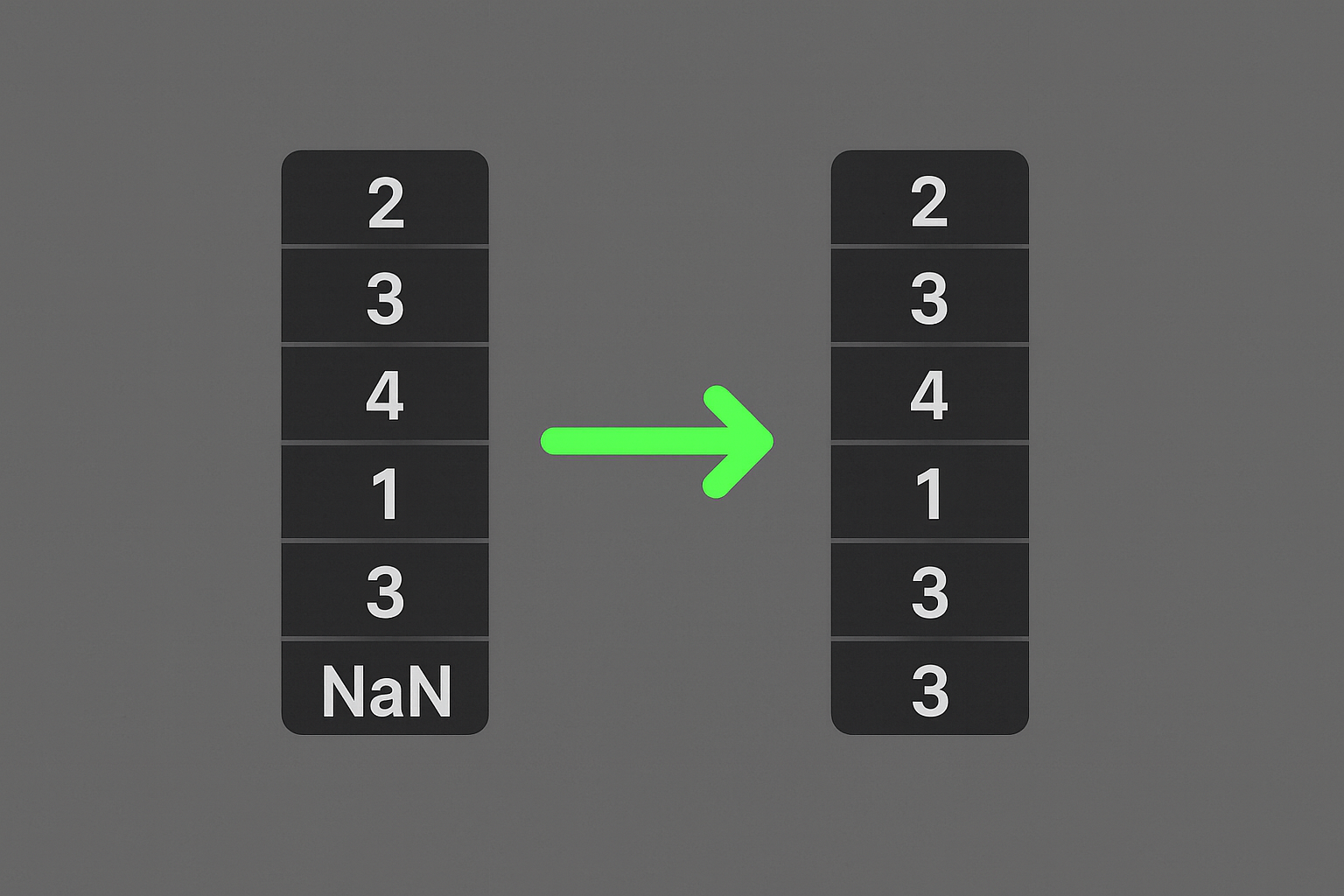
Consider the following dataset:
Status
Active
Inactive
Active
NaN
Active
The mode is Active, since it is the most frequent value. Applying mode imputation, the missing value is replaced as follows:
Status
Active
Inactive
Active
Active
Active
Mathematically, if we have a variable and a missing value , then:
Practical Implementation
🐍 Python
# Count missing values per column print(df.isna().sum()) # Calculate mode for each column modes = df.mode().iloc[0] print(modes) # Fill NaN values with the corresponding mode df.fillna(modes, inplace=True)
✅ Explanation
-
df.isna().sum()Shows how many missing values exist in each column. -
df.mode().iloc[0]Computes the mode per column and selects the first one in case multiple exist. -
df.fillna(modes, inplace=True)Automatically replaces NaN values with the mode of each respective column.
This approach is efficient, scalable, and ideal for real-world datasets with multiple features.
Advantages
- Easy to implement
- Computationally efficient
- Does not require complex models
- Ideal for categorical variables
Disadvantages
- May introduce bias into the dataset
- Reduces variability
- Does not capture complex relationships between variables
- Can over-represent a dominant category
If the percentage of missing data is high, this technique can significantly distort the original distribution.
When Should You Use It?
Mode imputation is appropriate when:
- The percentage of missing values is low ()
- The variable is categorical
- The mode accurately represents the dataset behavior
- High statistical precision is not required
It is not recommended when:
- Categories are highly dispersed
- Preserving the original distribution is critical
- The dataset is small
Best Practices
- Analyze missing data patterns (MCAR, MAR, MNAR)
- Measure the impact before and after imputation
- Document the applied technique
- Apply cross-validation when used in ML models
- Consider advanced techniques such as KNN or multiple imputation
Practical Case
Suppose we have a survey with the variable "Education Level":
Primary
Secondary
Secondary
NaN
University
Secondary
Mode = Secondary → the missing value is replaced with "Secondary"
This maintains consistency in the analysis, although it may artificially inflate this category.
Conclusion
Mode imputation is a fundamental technique in data preprocessing, especially when dealing with categorical variables. While its simplicity makes it attractive, it must be applied carefully and accompanied by an analysis of its impact on the dataset distribution.
In real-world environments, it is often combined with other cleaning strategies to balance simplicity, accuracy, and statistical representativeness.
FAQs
Does mode imputation always improve model performance? No. In some cases, it may introduce noise and bias.
Can it be used with numerical data? Yes, but it is generally not recommended unless the variable is discrete with repetitive values.
Is it better than deleting rows with NaN values? It depends on the context. Removing rows can reduce sample size and affect generalization.
Recommended Resources
Leave a Reply
Your email address will not be published. Required fields are marked *

Comments