Sigmoid Function Explained: Definition, Formula, Graph, and Applications in Machine Learning
The sigmoid function is one of the most classic and important mathematical functions in machine learning, especially in logistic regression and binary classification. Although modern deep learning frequently uses ReLU and other activations, understanding the sigmoid is essential for anyone learning neural networks or probability-based models.
In this guide, we cover what the sigmoid function is, why it matters, how it works mathematically, its advantages and disadvantages, and its use in real code examples.
What Is the Sigmoid Function?
The sigmoid function (also known as the logistic function)
transforms any real number into a value between 0 and 1.
This makes it ideal for probability estimation.
Mathematically, it is defined as:
Intuition Behind the Sigmoid Function
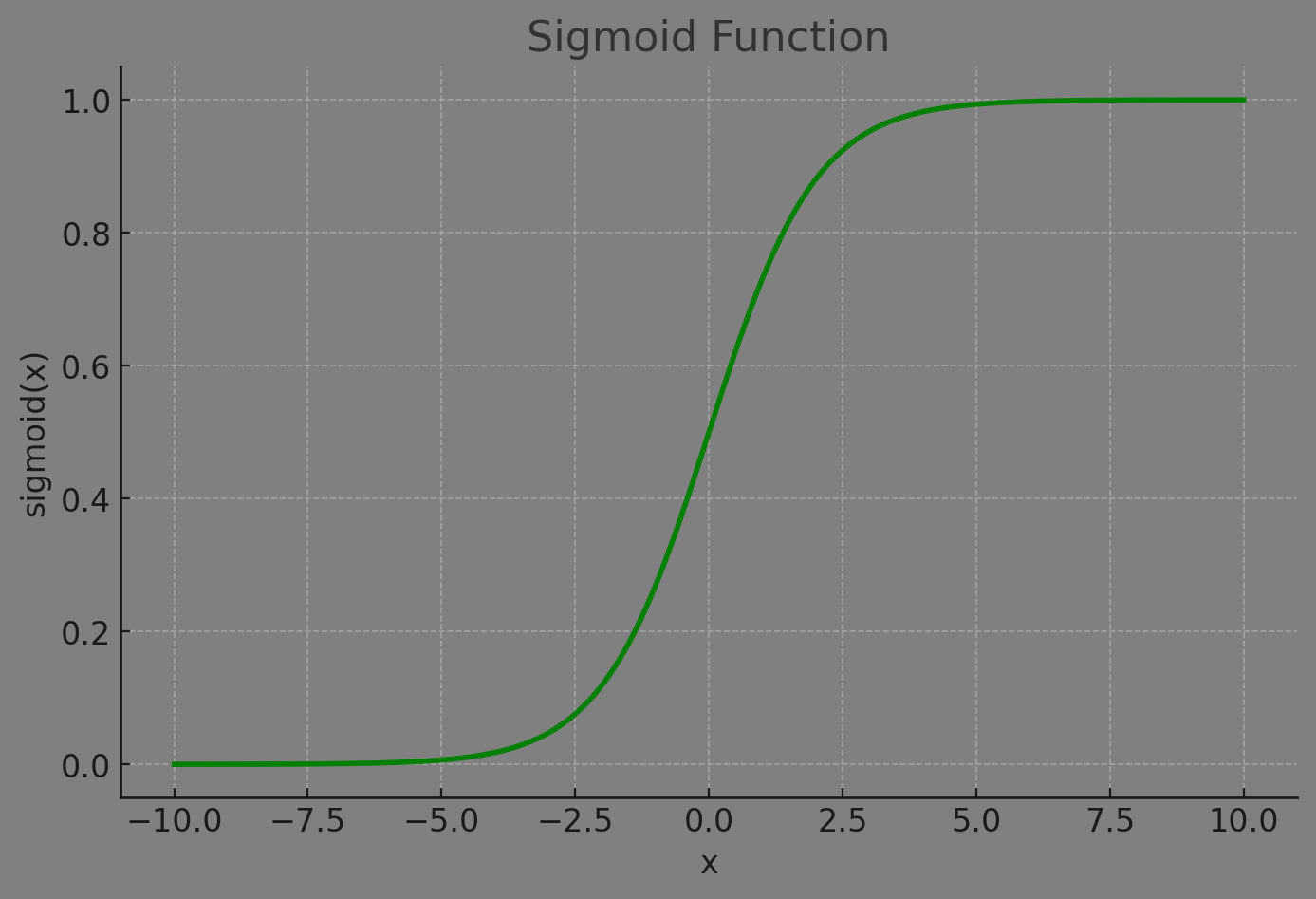
The sigmoid function has an S-shaped curve, meaning:
- Large positive values of (x) push the output close to 1
- Large negative values push the output close to 0
- At (x = 0), the output is exactly 0.5
This behavior makes sigmoid perfect for answering questions like:
"How likely is the input to be 1 instead of 0?"
Shape of the Sigmoid Function
The curve smoothly transitions between 0 and 1:
- Output range: (0, 1)
- Center point: 0.5
- Smooth gradient everywhere (but small near extremes)
Mathematical Properties
1. Derivative
The derivative of the sigmoid is elegant and extremely useful:
This simplifies gradient-based optimization such as backpropagation.
2. Limits
Why Is the Sigmoid Function Used in Machine Learning?
1. Models probabilities
Sigmoid converts raw model outputs into normalized probabilities.
2. Smooth gradients
Its continuous derivative enables effective gradient descent.
3. Used in binary classification
In logistic regression, the model predicts:
4. Appears in neural networks
Common in:
- Output layers for binary classification
- Some recurrent architectures (e.g., LSTMs use a variant)
Limitations of the Sigmoid Function
Even though it's widely used, sigmoid has some downsides:
❌ Vanishing gradients
For very large or small inputs, gradients become tiny, slowing learning.
❌ Outputs not zero-centered
Values are always positive, causing inefficient gradient behavior.
❌ Not ideal for deep hidden layers
ReLU and variants often perform better.
Sigmoid Function in Code
Python (NumPy)
import numpy as np def sigmoid(x): return 1 / (1 + np.exp(-x)) print(sigmoid(0)) # 0.5 print(sigmoid(5)) # ~0.993 print(sigmoid(-5)) # ~0.0067
TensorFlow / Keras
import tensorflow as tf x = tf.constant([0.0, 2.0, -2.0]) tf.nn.sigmoid(x)
PyTorch
import torch import torch.nn as nn sigmoid = nn.Sigmoid() sigmoid(torch.tensor([0.0, 3.0, -3.0]))
When Should You Use Sigmoid?
Use sigmoid when:
- You need probability outputs
- You're solving a binary classification problem
- You're modeling yes/no decisions
- You need a smooth "soft threshold"
Do not use sigmoid:
- In deep hidden layers
- When vanishing gradients become a problem
- For multi-class classification (use softmax instead)
FAQ About the Sigmoid Function
Is sigmoid the same as logistic regression?
Not exactly. Logistic regression uses sigmoid as its probability output.
Why is sigmoid used at the output layer?
Because it maps values to the range (0, 1), ideal for probability.
Is sigmoid still used in modern neural networks?
Yes, but mostly in:
- Binary output layers\
- Certain recurrent architectures (gates in LSTMs)
Conclusion
The sigmoid function remains a foundational concept in machine learning. Its ability to map real numbers to the range (0, 1) makes it indispensable for probability modeling, logistic regression, and binary classification.
Even though newer activation functions dominate deep learning, mastering sigmoid is critical for understanding how neural networks and probabilistic models operate.
If you're learning AI, this is one function you absolutely must understand.
Leave a Reply
Your email address will not be published. Required fields are marked *

Comments